
データが平均から どのくらい ばらついているか の指標
『 分析・観察から得たデータが平均からどのくらい ばらついているか 』を示す指標になるのが分散である1).
分散 = (すべてのデータについて(データ – 平均)2 )÷ データの数
データ – 平均 については マイナスの値になることがあるので 2 乗している1).
1) Robert R. Sokal, F. James Rohlf 藤井宏一(訳) 生物統計学 1983 共立出版 P.47 – 49
ChatGPT – 4 による分散を算出する R スクリプト
分散を算出する R スクリプトを以下に示す.
# エクセルファイルのパス
file_path <- “C:/Users/あなたのユーザー名/Desktop/data.xlsx”
# エクセルファイルからデータを読み込む
data <- read_excel(file_path)
# データの列名を指定して、数値データを取得
# ここでは “Column1” という列名を仮定しています
numeric_data <- data$Column1
# 分散を算出
variance <- var(numeric_data)
# 分散を新しいシートに書き込むために、データフレームに変換
variance_df <- data.frame(Variance = variance)
# 既存のエクセルファイルに新しいシートを追加し、分散を書き込む
wb <- loadWorkbook(file_path)
addWorksheet(wb, “Variance”)
writeData(wb, sheet = “Variance”, variance_df)
# エクセルファイルを保存
saveWorkbook(wb, file_path, overwrite = TRUE)
print(“分散の算出が完了し、エクセルファイルに書き込みました。”)
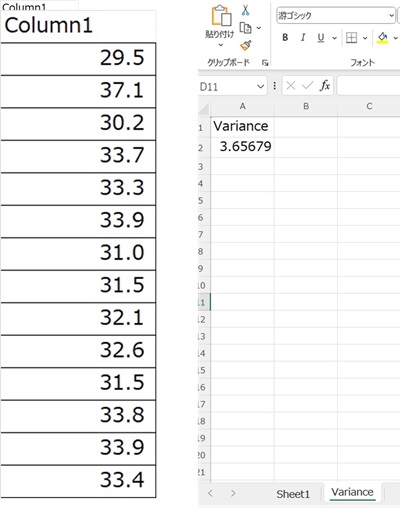
データのエクセルファイルおよび算出された分散を以下に示す.
平均を算出する Python スクリプトを以下に示す.
import pandas as pd
# エクセルファイルのパス
file_path = “C:/Users/あなたのユーザー名/Desktop/data.xlsx”
# エクセルファイルからデータを読み込む
data = pd.read_excel(file_path)
# データの列名を指定して、数値データを取得
# ここでは “Column1” という列名を仮定しています
numeric_data = data[‘Column1’]
# 分散を算出
variance = numeric_data.var()
# 分散を新しいデータフレームに変換
variance_df = pd.DataFrame({‘Variance’: [variance]})
# 既存のエクセルファイルに新しいシートを追加し、分散を書き込む
with pd.ExcelWriter(file_path, mode=’a’, engine=’openpyxl’) as writer:
variance_df.to_excel(writer, sheet_name=’Variance’, index=False)
print(“分散の算出が完了し、エクセルファイルに書き込みました。”)
