Ver. 2 前回の更新 2024 年 8 月 4 日
データの集団群(例 対照,処理1,処理2,処理3,処理4)に対して,検定を繰り返すことは,多重性の問題を引き起こすことになる.かっては,代表的な統計解析ソフトである SPSS でも,一元配置分散分析をしてから,多重検定をするように設定されていた.しかし,現在では,データの集団群に正規分布性のの検出をしてから,統計的仮説検定をすることは,多重性の問題をまねくので統計学的にはよくない行為とされることが多くなってきている.こうした理由から,正規分布の検定をすることなく,統計的仮説検定をすることが求められてきている.
分析・観察して得たデータが 『 正規分布しているかどうかを確かめること 』(1) ,(2)は 統計解析の ステップ 3 である.ステップ 1 は 『 特性が均一の個体を選ぶこと』,ステップ 2 は 『 外れ値を除去すること』になる.
(1) Robert R. Sokal, F. James Rohlf 藤井宏一(訳) 生物統計学 1983 共立出版 P.106
(2) 池田郁男 改訂増補版:統計検定を理解せずに使っている人のために Ⅰ2019 化学と生物 57(8) P.498
正規分布の検出について
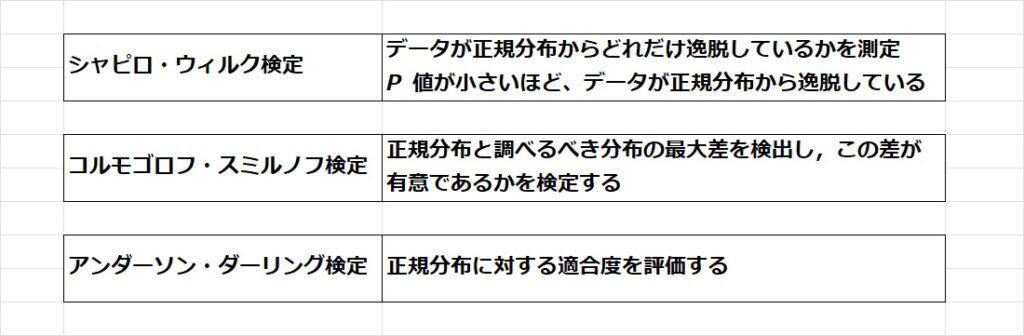
正規分布しているかどうかを検定する主なものには,シャピロ・ウィルクス検定,コスモゴロフ・スミルノフ検定,アンダーソン・ダーリング検定などがある.これらの特性を以下に示す.
コスモゴロフ・スミルノフ検定を Python スクリプトで示す
# Python によるコルモゴロフ・スミルノフ検定
import pandas as pd
from scipy.stats import kstest
from openpyxl import load_workbook
# エクセルファイルのパスを指定
file_path = ‘C:/Users/あなたのファイル/Desktop /data.xlsx’
# エクセルファイルの読み込み
df = pd.read_excel(file_path)
# コルモゴロフ・スミルノフ検定の実行
data = df.iloc[:, 0] # 最初の列を使用
stat, p_value = kstest(data, ‘norm’)
# 検定結果の作成
result_df = pd.DataFrame({
‘Test’: [‘Kolmogorov-Smirnov’],
‘Statistic’: [stat],
‘p-value’: [p_value]
})
# 正規性の判断
if p_value < 0.05:
conclusion = “データは正規分布に従っていないと判断されます。”
else:
conclusion = “データは正規分布に従っていると判断されます。”
# 検定結果に判断を追加
result_df[‘Conclusion’] = [conclusion]
# 結果を新しいシートに書き込む
with pd.ExcelWriter(file_path, engine=’openpyxl’, mode=’a’) as writer:
result_df.to_excel(writer, sheet_name=’KS_Test_Result’, index=False)
print(“コルモゴロフ・スミルノフ検定の結果がエクセルファイルに書き込まれました
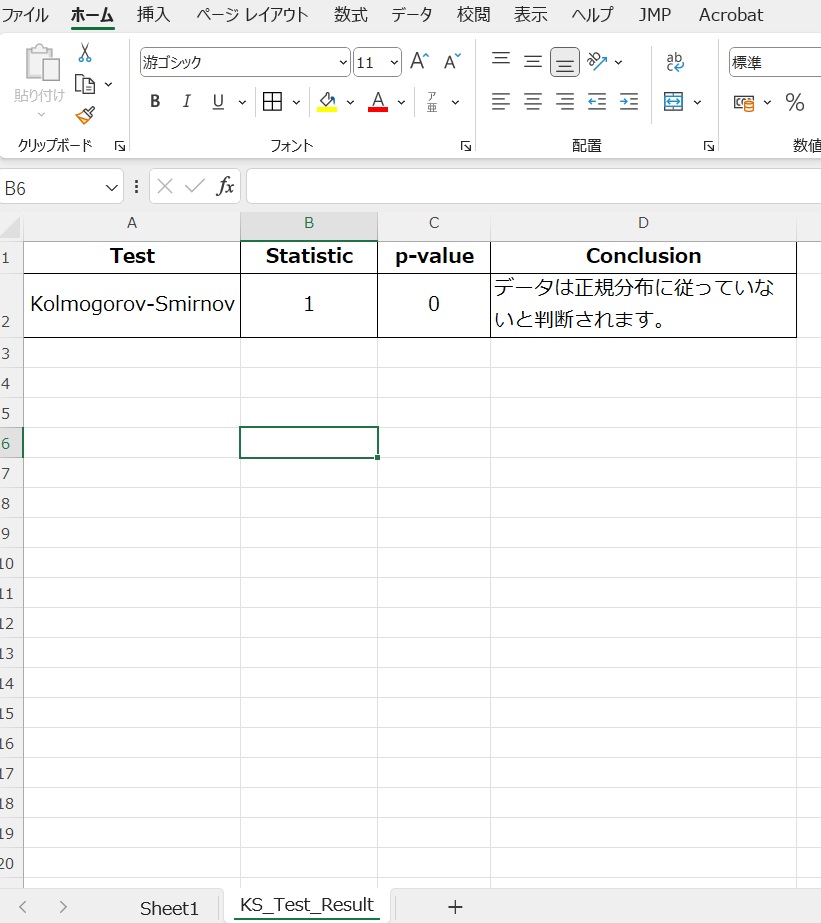
エクセルファイルを下に示す.

●検定結果のエクセル sheet を以下に示す.