
Ver. 2 前回の更新 2024 年 10 月 28 日
データの集団群(例 対照,処理1,処理2,処理3,処理4)に対して,検定を繰り返すことは,多重性の問題を引き起こすことになる.かっては,代表的な統計解析ソフトである SPSS でも,一元配置分散分析をしてから,多重検定をするように設定されていた.しかし,現在では,データの集団群に外れ値の検定をしてから,つづいて統計的仮説検定検定をすることは,多重性の問題をまねくので統計学的にはよくない行為とされることが多くなってきている.したがって,外れ値の検定をすることなく,統計的仮説検定をすることが求められるようになってきている.
外れ値とは測定・観察したデータのうち真の値からかけ離れた数値を示すデータのことである.外れ値はヒューマンエラーで起こることが多いので,統計解析をするうえで,最も大切なことは, 外れ値の検出を使わないですむように分析・観察をすること になる.また,生物は個体差が大きいので分析・観察が正しい方法で行われていても外れ値はデータとして得られてしまう.
外れ値の検出をすることはデータ改ざんではない
このブログは「 統計学を道具として使う 」ことを 1 つの目的としている.ヒューマンエラー以外の原因で生じた外れ値については,これらを削除することで,正しい統計解析とそれらの結果による考察をすることが可能になる.外れ値はかならずといってよいほどデータに存在するので,データ補正として外れ値の検出をすることは,データ改ざんに該当しない.
市販の統計解析ソフト JMP では,ロバスト推定の外れ値の検出および分位点範囲の外れ値の検出などが利用できる.外れ値の検出方法を (1) ロバスト推定による外れ値の検出,(2) ロバスト推定によらない外れ値の検出にわけ,それぞれどのような場合に利用するかを表に示した.

外れ値の検出については,ChatGPT – 4 や書籍で調べることをすすめる.ChatGPT – 4 も しばしば まちがえるので,校正がしっかりしている書籍で調べなおすことが必要になるのである.
ChatGPT – 4 による 外れ値検出の Python スクリプト
パソコンのデスクトップにoutliners というエクセルファイルを作成する.データは正答数で列の方向に並んでいる.

Pycharm で実行し,エクセルファイルの新しいシートに示された結果を以下に示す.
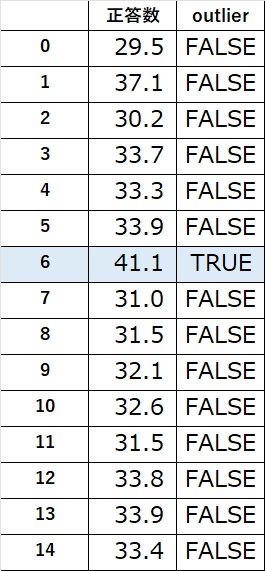
外れ値はTRUE,正しいと思われるデータは FALSE で示される.
Python スクリプトを示す.
# 中央値絶対偏差(MAD)を使ったはずれ値検定
import pandas as pd
import numpy as np
# ファイルパス
file_path = ‘C:/Users/あなたのファイル/Desktop/data.xlsx’
sheet_name = ‘Sheet1’
# Excelファイルを読み込む
data = pd.read_excel(file_path, sheet_name=sheet_name)
# 中央値絶対偏差 (MAD) を用いた外れ値検定
def mad_based_outlier(points, threshold=3.5):
median = np.median(points)
diff = np.abs(points – median)
mad = np.median(diff)
modified_z_score = 0.6745 * diff / mad
return modified_z_score > threshold
# 外れ値フラグをデータに追加し、True/False を より明確なラベルに変換
data[‘outlier’] = mad_based_outlier(data[‘YourDataColumn’])
data[‘outlier’] = data[‘outlier’].map({True: ‘外れ値’, False: ‘正常’})
# 新しいシートに結果を書き込む
with pd.ExcelWriter(file_path, engine=’openpyxl’, mode=’a’) as writer:
data.to_excel(writer, sheet_name=’Outliers’)
print(“外れ値検定の結果がExcelファイルに書き込まれました。”)
つぎは,おなじはMAD を使った外れ値の検出を R スクリプトで示してみることにする.
# R による中央値絶対偏差(MAD)を使ったはずれ値検定
# 必要なパッケージの読み込み
library(readxl)
library(openxlsx)
# ファイルパスとシート名
file_path <- ‘C:/あなたのフォルダ/Desktop/data.xlsx’
sheet_name <- ‘Sheet1’
# Excelファイルを読み込む
data <- read_excel(file_path, sheet = sheet_name)
# 中央値絶対偏差 (MAD) を用いた外れ値検定
mad_based_outlier <- function(points, threshold = 3.5) {
median <- median(points, na.rm = TRUE)
diff <- abs(points – median)
mad <- median(diff, na.rm = TRUE)
modified_z_score <- 0.6745 * diff / mad
return(modified_z_score > threshold)
}
# 外れ値フラグをデータに追加し、True/False を より明確なラベルに変換
data$outlier <- mad_based_outlier(data$正答数)
data$outlier <- ifelse(data$outlier, ‘外れ値’, ‘正常’)
# 新しいシートに結果を書き込む
write.xlsx(data, file = file_path, sheetName = “Outliers”, append = TRUE)
print(“外れ値検定の結果がExcelファイルに書き込まれました。”)
